GPT models’ learning and disclosure of personal data: An experimental vulnerability analysis

Medium.com • April 10, 2023
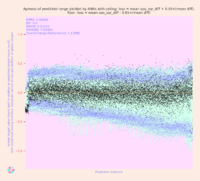
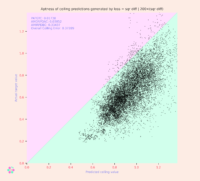
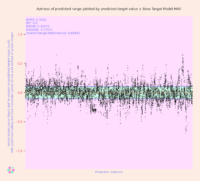
SUMMARY: The possible gathering, retention, and later dissemination of individuals’ personal data by AI systems utilizing Generative Pretrained Transformers (GPTs) is an area that’s of growing concern from legal, ethical, and business perspectives. To develop a better understanding of at least one aspect of the privacy risks involved with the rapidly expanding use of GPT-type systems and other large language models (LLMs) by the public, we conducted an experimental analysis in which we prepared a series of GPT models that were fine-tuned on a Wikipedia text corpus into which we had purposefully inserted personal data for hundreds of imaginary persons. (We refer to these as “GPT Personal Data Vulnerability Simulator” or “GPT-PDVS” models.) We then used customized input sequences (or prompts) to seek information about these individuals, in an attempt to ascertain how much of their personal data a model had absorbed and to what extent it was able to output that information without confusing or distorting it. The results of our analysis are described in this article. They suggest that – at least with regard to the class of models tested – it’s unlikely for personal data to be “inadvertently” learned by a model during its fine-tuning process in a way that makes the data available for extraction by system users, without a concentrated effort on the part of the model’s developers. Nevertheless, the development of ever more powerful models – and the existence of other avenues by which models might possibly absorb individuals’ personal data – means that the findings of this analysis are better taken as guideposts for further scrutiny of GPT-type models than as definitive answers regarding any potential InfoSec vulnerabilities inherent in such LLMs.